



Die logistische Regression ist ein statistisches Analyseverfahren, um die Wahrscheinlichkeit des Eintritts eines Ereignisses zu modellieren und zu analysieren, wenn die abhängige Variable dichotom kodiert ist.
„Im Gegensatz zur linearen Regression, die kontinuierliche abhängige Variablen vorhersagt, eignet sich die logistische Regression, um Vorhersagen über binäre Ergebnisse zu treffen…“
Im Gegensatz zur linearen Regression, die kontinuierliche abhängige Variablen vorhersagt, eignet sich die logistische Regression, um Vorhersagen über binäre Ergebnisse zu treffen – also Fälle, in denen die Ergebnisvariable zwei mögliche Werte annimmt, etwa „ja“ vs. „nein“, „erfolgreich“ vs. „nicht erfolgreich“. Das Modell schätzt demnach die Wahrscheinlichkeit, dass eine bestimmte Beobachtung zu einer der beiden Kategorien gehört, basierend auf einer oder mehreren unabhängigen Variablen. Die Ergebnisse werden häufig in Form von Odds Ratios ausgedrückt, die anzeigen, wie die Odds (Chancen) für das Eintreten des Ereignisses durch die unabhängigen Variablen beeinflusst werden. Die alternative Darstellung der Ergebnisse in Koeffizienten wird in diesem Artikel jedoch ebenfalls thematisiert.
Logistische Regression in RStudio – Unser Anwendungsbeispiel
In unserem Anwendungsbeispiel wird eine logistische Regression angewandt, um zu untersuchen, welche Faktoren die Entscheidung beeinflussen, ob jemand ein Hochschulstudium aufnimmt oder nicht. Diese binäre abhängige Variable (Hochschulstudium ja/nein) wird in Beziehung gesetzt zu verschiedenen unabhängigen Variablen, die potenzielle Einflussfaktoren darstellen. Zu diesen Variablen gehören der akademische Hintergrund der Eltern, die schulische Leistung, der Zugang zu Bildungsressourcen sowie die Motivation zur Bildung. Durch die Analyse dieser Beziehungen kann berechnet werden, welche Faktoren die Entscheidung für oder gegen ein Hochschulstudium signifikant beeinflussen.
Die theoretische Annahme hinter dem akademischen Hintergrund der Eltern ist, dass Eltern mit einem höheren akademischen Abschluss in der Regel mehr Wissen über das Bildungssystem haben und ihre Kinder besser bei der Vorbereitung auf ein Hochschulstudium unterstützen können. Zudem setzen sie möglicherweise höhere Bildungsstandards und Erwartungen (Buchmann & DiPrete, 2006). Bezüglich der schulischen Leistung wird angenommen, dass Schüler:innen mit besseren schulischen Leistungen tendenziell bessere Chancen haben, die Zulassungskriterien für Hochschulen zu erfüllen und über das notwendige akademische Selbstvertrauen verfügen, um ein Studium aufzunehmen Der Zugang zu Bildungsressourcen wie Büchern, Computern und Internet sowie zusätzliche Unterstützung durch Nachhilfe oder Förderprogramme kann die akademische Vorbereitung verbessern und somit die Wahrscheinlichkeit eines Hochschulstudiums erhöhen. Eine hohe intrinsische Motivation zur Bildung kann die Bereitschaft und den Wunsch steigern, ein Hochschulstudium aufzunehmen, da die Studierenden ein starkes persönliches Interesse und Engagement für ihre akademische Entwicklung zeigen (Kori et al., 2016).
Datenvorbereitung und Modellanpassung
Um eine logistische Regression in R mit Daten durchzuführen, die in einer Excel-Datei (.xlsx) vorliegen, gehen wir schrittweise vor und verwenden die Variablen aus unserem Übungsdatensatz, der hier zum Download bereitsteht.
Schritt 1
R und RStudio installieren
Die Analyse beginnt mit der Installation von R und RStudio. R kann von der CRAN-Website heruntergeladen werden, während die aktuelle Version von RStudio über diesen Link zu finden ist.
Schritt 2
Notwendige Pakete installieren
Um mit Excel-Dateien (.xlsx) in R zu arbeiten, wird das Paket „readxl“ benötigt. Falls dieses noch nicht installiert wurde, ist RStudio zu öffnen und folgender Befehl auszuführen:
install.packages("readxl")
Schritt 3
Die Excel-Datei in R laden
Nun wird das „readxl“ Paket geladen und die Excel-Datei eingelesen. Der Pfad „Pfad/zur/Datei.xlsx“ wird durch den tatsächlichen Pfad zur Excel-Datei auf dem jeweiligen Endgerät geändert:
library(readxl)
probedatensatz <- read_excel("Downloads/probedatensatz.xlsx")
View(probedatensatz)
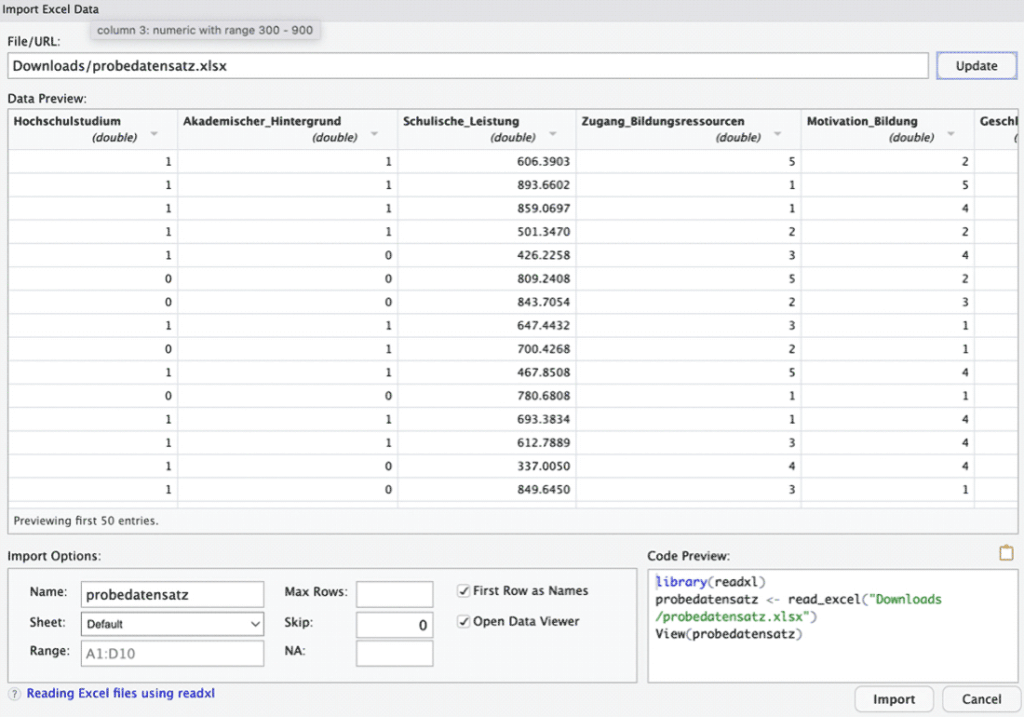
Alternativ kann der Datensatz manuell über den Reiter „Import Dataset“ eingepflegt werden (Abbildung 1). Dieser befindet sich im oberen linken Teil von RStudio.
Schritt 4
Datenstruktur überprüfen
Anschliessend ist es sinnvoll, einen Blick auf die Struktur des Datensatzes zu werfen, um sicherzustellen, dass alles korrekt eingelesen wurde:
str(probedatensatz)
Schritt 5
Logistische Regression durchführen
Im vorliegenden Fall soll untersucht werden, wie der akademische Hintergrund der Eltern („Akademischer_Hintergrund”), die schulische Leistung („Schulische_Leistung”), der Zugang zu Bildungsressourcen („Zugang_Bildungsressourcen”), und die Motivation zur Bildung („Motivation_Bildung”) die Wahrscheinlichkeit beeinflussen, ein Hochschulstudium („Hochschulstudium”) aufzunehmen. Dazu wird die „glm()” Funktion mit der Familie „binomial” genutzt:
modell <- glm(Hochschulstudium ~ Akademischer_Hintergrund + Schulische_Leistung + Zugang_Bildungsressourcen + Motivation_Bildung, family=binomial, data=probedatensatz)
Schritt 6
Modellergebnisse anzeigen
Um eine Zusammenfassung des Modells zu erhalten und die Effekte der unabhängigen Variablen auf die Wahrscheinlichkeit zu sehen, wird verwendet:
summary(modell)
Dieser Befehl liefert eine detaillierte Ausgabe, einschliesslich der Schätzungen der Regressionskoeffizienten („Estimate”), deren Standardfehler („Std. Error”), den z-Wert („z value”), und die zugehörigen p-Werte („Pr(>|z|)”), die die Signifikanz der Koeffizienten testen.
Die logistischen Regressionskoeffizienten können anschliessend mithilfe des folgenden Befehls in Odds Ratios transformiert werden:
odds <- exp(coefficients) odds
Die Ergebnisse der logistischen Regression basierend auf den Koeffizienten bieten eine direkte Einsicht in die Art und Stärke des Zusammenhangs zwischen den unabhängigen Variablen und der Wahrscheinlichkeit, dass jemand ein Hochschulstudium aufnimmt. Im Gegensatz zu den Odds Ratios, die das Verhältnis der Chancen beschreiben, zeigen die Koeffizienten direkt, wie eine Einheitsänderung in der unabhängigen Variable die Log-Odds (logarithmierte Chancen) der abhängigen Variable beeinflusst.
Bewertung der statistischen Signifikanz
In beiden Fällen ist die Signifikanz der Koeffizienten durch den Blick auf die p-Werte („Pr(>|z|)“ zu interpretieren. Ein p-Wert unter 0.05 deutet darauf hin, dass der Koeffizient statistisch signifikant ist. Bei der Interpretation der p-Werte in einer logistischen Regression ist es wichtig zu verstehen, dass der p-Wert die Wahrscheinlichkeit angibt, dass das beobachtete Ergebnis (oder ein extremeres) unter der Annahme der Nullhypothese eintritt. Die Nullhypothese besagt in diesem Kontext, dass es keinen Zusammenhang zwischen der unabhängigen Variablen und der abhängigen Variablen gibt. Eine häufig verwendete Signifikanzschwelle ist die 5%-Grenze (p < 0.05). Wenn der p-Wert einer unabhängigen Variablen kleiner als 0.05 ist, wird die Nullhypothese verworfen, und es wird angenommen, dass ein statistisch signifikanter Zusammenhang zwischen dieser unabhängigen Variablen und der abhängigen Variablen besteht. Das bedeutet, dass die Wahrscheinlichkeit, dass das Ergebnis zufällig ist, weniger als 5% beträgt. Im vorliegenden Fall würde dies darauf hinweisen, dass die betreffende Variable einen signifikanten Einfluss auf die Entscheidung hat, ob jemand ein Hochschulstudium aufnimmt oder nicht. Es ist jedoch wichtig zu beachten, dass statistische Signifikanz nicht gleichbedeutend mit praktischer Relevanz ist. Auch wenn ein p-Wert unter 0.05 liegt, sollte die Stärke des Zusammenhangs und der Kontext der Studie berücksichtigt werden, um die tatsächliche Bedeutung des Ergebnisses zu beurteilen.
Darstellung der Ergebnisse in Koeffizienten
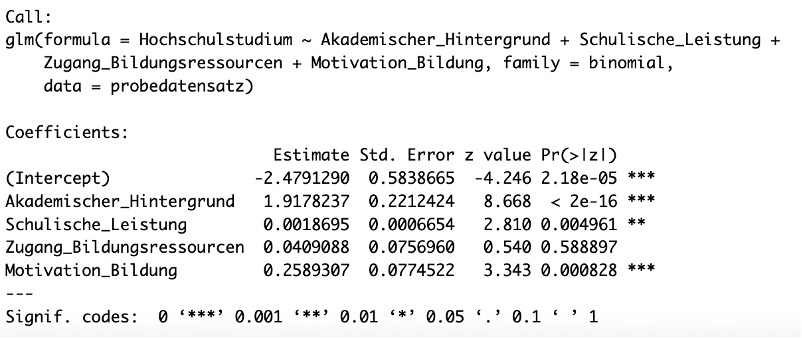
- Akademischer Hintergrund: Der Koeffizient von 1.918 zeigt, dass, wenn mindestens ein Elternteil Akademiker:in ist, die Log-Odds, ein Hochschulstudium aufzunehmen, um etwa 1.918 Einheiten steigen – verglichen mit Proband:innen, deren Eltern nicht akademisch gebildet sind. Der signifikante p-Wert bestätigt den starken positiven Einfluss des akademischen Hintergrunds.
- Schulische Leistung: Der Koeffizient von 0.002 bedeutet, dass für jeden zusätzlichen Punkt in der schulischen Leistung die Log-Odds, ein Hochschulstudium aufzunehmen, um 0.002 Einheiten steigen. Obwohl sowohl statistisch signifikant als auch positiv, ist dieser Einfluss relativ gering.
- Zugang zu Bildungsressourcen: Mit einem Koeffizienten von 0.041 steigen die Log-Odds für die Aufnahme eines Hochschulstudiums um 0.041 Einheiten für jede zusätzliche Stufe des Zugangs zu Bildungsressourcen. Dies deutet auf einen positiven, aber moderaten Einfluss hin. Allerdings zeigt der zugehörige p-Wert, dass der Zusammenhang nicht signifikant ist.
- Motivation zur Bildung: Der signifikante Koeffizient von 0.259 zeigt, dass mit jeder höheren Stufe der Motivation die Log-Odds, ein Hochschulstudium aufzunehmen, um 0.259 Einheiten steigen. Dies unterstreicht die Bedeutung der Motivation zur Bildung.
Logistische Regression und Odds Ratio

Odds Ratio illustrieren, wie bestimmte Faktoren die Wahrscheinlichkeit beeinflussen, dass eine Person ein Hochschulstudium aufnimmt. Ein herausstechendes Ergebnis ist der Einfluss des akademischen Hintergrunds: Proband:innen, bei denen mindestens ein Elternteil Akademiker:in ist, haben eine fast siebenfach höhere Chance, ein Hochschulstudium zu beginnen, verglichen mit jenen, deren Eltern nicht akademisch gebildet sind. Dies unterstreicht die zentrale Bedeutung des familiären Bildungshintergrunds für die Bildungsentscheidungen der Kinder.
Die schulische Leistung zeigt ebenfalls einen positiven Effekt, allerdings ist dieser mit einem Anstieg der Odds um das 1,002-fache pro zusätzlichem Punkt in der schulischen Leistung sehr gering. Dies bedeutet, dass zwar eine bessere schulische Leistung grundsätzlich die Wahrscheinlichkeit eines Hochschulstudiums erhöht, der Effekt jedoch im Vergleich zum Einfluss des akademischen Hintergrunds relativ schwach ist.
Interessanterweise hat der Zugang zu Bildungsressourcen einen erkennbaren Einfluss, wobei jede zusätzliche Stufe auf der Skala des Zugangs zu solchen Ressourcen die Odds auf ein Hochschulstudium um das 1,04-fache erhöht. Das Ergebnis deutet darauf hin, dass Ressourcen wie Nachhilfe, Bibliotheken und technologische Hilfsmittel zumindest eine gewisse Rolle spielen könnten.
Weiterhin bemerkenswert ist die Rolle der Motivation zur Bildung. Die Analyse zeigt, dass mit jeder höheren Stufe der Motivation zur Bildung die Odds, ein Hochschulstudium zu beginnen, um das 1,29-fache steigt. Dieses Ergebnis bekräftigt die Wichtigkeit intrinsischer Motivation und einer positiven Einstellung zur Bildung als Treiber für die Entscheidung, weiterführende Bildungswege zu beschreiten.
Zusammenfassend legt die logistische Regression nahe, dass sowohl der familiäre Bildungshintergrund als auch die persönliche Einstellung zur Bildung entscheidende Faktoren sind, die beeinflussen, ob jemand ein Hochschulstudium aufnimmt. Der Einfluss der schulischen Leistung und des Zugangs zu Bildungsressourcen ist ebenfalls vorhanden, wenngleich in einem geringeren Ausmass.
Zusätzliche Tipps
- Kritischer Blick: Auch statistisch signifikante Ergebnisse sollten im Kontext theoretischer Überlegungen und der vorhandenen Literatur interpretiert werden.
- Störvariablen: Der Einschluss relevanter Kontrollvariablen kann helfen, die Beziehung zwischen den Hauptvariablen genauer zu modellieren.
- Überprüfung der Modellpassung: Zusätzliche Diagnostik und Tests auf die Modellpassung können helfen zu beurteilen, wie gut das Modell die Daten abbildet.
Zusammenfassung der wichtigsten Punkte:
- Datenvorbereitung: Vor der Durchführung der Analyse müssen die Daten sorgfältig bereinigt und korrekt formatiert werden. Es ist wichtig sicherzustellen, dass die abhängige Variable dichotom kodiert ist (z.B. 0 für nein, 1 für ja). Die Datenstruktur wird mit Funktionen wie „str()” überprüft, um sicherzustellen, dass alle Variablen korrekt eingelesen wurden und keine fehlenden Werte vorliegen.
- Durchführung der logistischen Regression: Die logistische Regression in R wird mithilfe der „glm()”-Funktion mit der Familie „binomial” durchgeführt, um die Wahrscheinlichkeit des Eintritts eines binären Ereignisses (z.B. Hochschulstudium ja/nein) zu modellieren. Die Modellformel spezifiziert die abhängige Variable und die unabhängigen Variablen, die potenzielle Einflussfaktoren darstellen.
- Interpretation der Modellergebnisse: Die Modellergebnisse werden in Form von Koeffizienten oder Odds Ratios interpretiert. Koeffizienten zeigen die Änderung der Log-Odds an, während Odds Ratios anzeigen, wie sich die Chancen für das Eintreten des Ereignisses mit jeder Einheit der unabhängigen Variablen ändern. Positive Koeffizienten und Odds Ratios grösser als 1 deuten auf einen positiven Einfluss der unabhängigen Variablen hin. Odds Ratios sind oft intuitiver zu verstehen, da sie zeigen, wie sich die Chance (nicht die Wahrscheinlichkeit) des Eintretens eines Ereignisses mit jeder Einheit der unabhängigen Variablen ändert.
- Bewertung der statistischen Signifikanz: p-Werte werden verwendet, um die statistische Signifikanz der Koeffizienten zu bewerten. Ein p-Wert unter 0.05 (5%-Grenze) zeigt an, dass der Zusammenhang zwischen der unabhängigen und der abhängigen Variablen statistisch signifikant ist. Das bedeutet, dass die Wahrscheinlichkeit, dass das Ergebnis zufällig ist, weniger als 5% beträgt.






